はじめてのOSコードリーディング 第1,2,3章の個人的メモ【Unix v6】

はじめに
私の本業では、今はAndroidのアプリ開発をメインで行なっています (いわゆるスマホアプリとは少し違いますが)。
下回りとの連携部分を実装することもあるのですが、正直なとこと下回りで実際にどんなことが起きているのかはよくわかっていませんでした。
そこで、ソフトウェアの下回り == OS という安直な考えで、「はじめてのOSコードリーディング – UNIX V6で学ぶカーネルのしくみ」という本を読んでみることにしました。

本記事は、私がわからないなりに理解しようと努めた足跡です。
もしかしたら誤読、誤解釈があるかもしれませんがご了承いただけると幸いです。
本を読む前に
ソースコード
ソースコードは本書では http://man.cat-v.org/unix-6th/ のページが紹介されていますが、 とある方がGithubにコピーを掲載しているのでそちらを使わせていただくことにしました。
コードをクローンして、CLionなどのIDEを使って手元でコードを追えるようにしておきます。
C言語のこと
私はC/C++について大学で学んでいたので、知識は多少あります。
が、Unix v6で使われているCは、pre K&R (C89以前のC言語のこと) らしく、私の知識・経験と比較するとほとんど別の言語に感じました。
pre K&R を学ぶことが本学習のメインでは無いので、「なんとなく理解して妥協する」ことにします。
ただし、共通する構文については理解しておく必要がありそうです (構造体とかポインタとか)。
アセンブリのこと
アセンブリについても、多少知識が必要です。
私は大学で、アセンブリ (x86) を少しだけ学びましたが、今回扱うアセンブリはPDP-11用のアセンブリです。
アセンブラによって構文が違う (方言がある) ので、こちらも先のpre K&Rと同じく、なんとなく共通項を理解していることが大事です。
例えば、レジスタの存在やプログラムカウンタの存在については、最初に理解しておく必要がありそうです。
ちなみにレジスタはメモリよりもアクセスコストが少ない小さな記憶領域です。
プログラムカウンタもレジスタの一種で、どの命令行を次に実行するかを示す情報です。
PDP-11/40のアセンブリについては下記の記事にまとめています。

第1~3章のメモ
PDP-11/40の構成
実装の話ではないですが、大事なことなので整理します。
PDP-11/40は大別して3種類の大事なレジスタを持っています。
汎用レジスタ群、PSW (Processor Status Word)、MMU (Memory Management Unit) です。
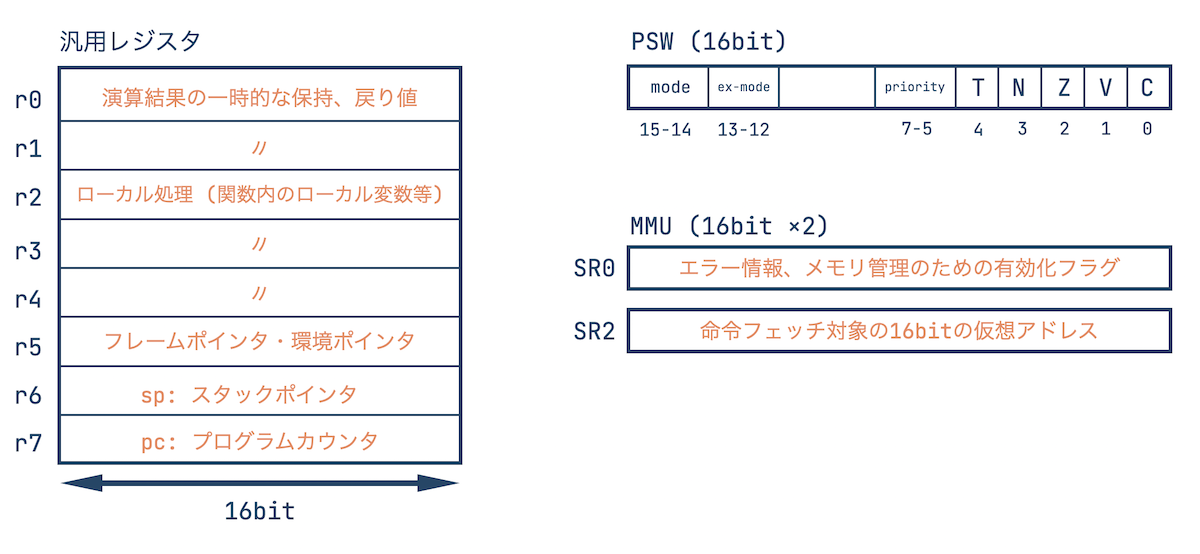
CPUの処理を単純化すると下記をひたすら繰り返しています。
- pc (プログラムカウンタ) が指すアドレスの命令文を読む
- 命令を解析
- 命令を実行
- PSWやpcなどのレジスタ、メモリ内容を必要に応じて書き換える
こう考えるととてもシンプルです。
proc構造体とuser構造体
一貫して登場する重要な構造体として、proc (sys/proc.h) とuser (sys/user.h)があります。
前提として、procはその名の通りプロセスを表す構造体で、その配列 proc[] で各エントリを管理しています。
コードをみると、proc[NPROC] とあり、NPROCはsys/param.hで 50と定義されています。
“user構造体” と言っても、私たちが最初に思い浮かぶ人間のユーザを指しているわけではなく、procを補足するための情報を管理する構造体という理解が良さそうです。
userには、プロセスに割り当てられた物理メモリ領域 (テキストセグメント、データセグメント) の情報が格納されています。
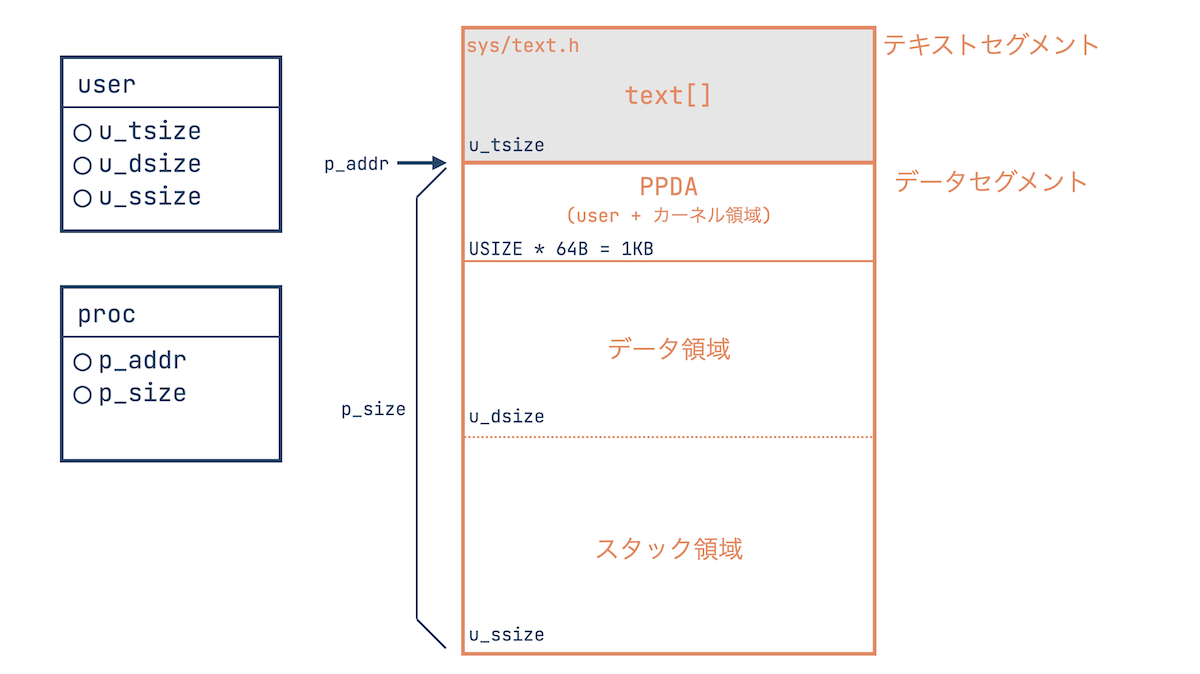
仮想アドレス変換
各プロセスには64KB (0x000 ~ 0xffff bit) の仮想アドレス空間が与えられます。
そしてその仮想アドレスが物理アドレスに変換され、メモリにアクセスを行う、といった処理になります。
仮想アドレスは16bit、物理アドレスは18bit。
仮想アドレスから物理アドレスへの変換は、MMU (Memory Management Unit) が APR (Active Page Register) と呼ばれるレジスタを使って行われるようです。
また、APRは PAR (Page Address Register) と PDR (Page Description Register) とよばれる2組のレジスタを指しています。
仮想アドレスから物理アドレスへの変換例を図にしてみました。
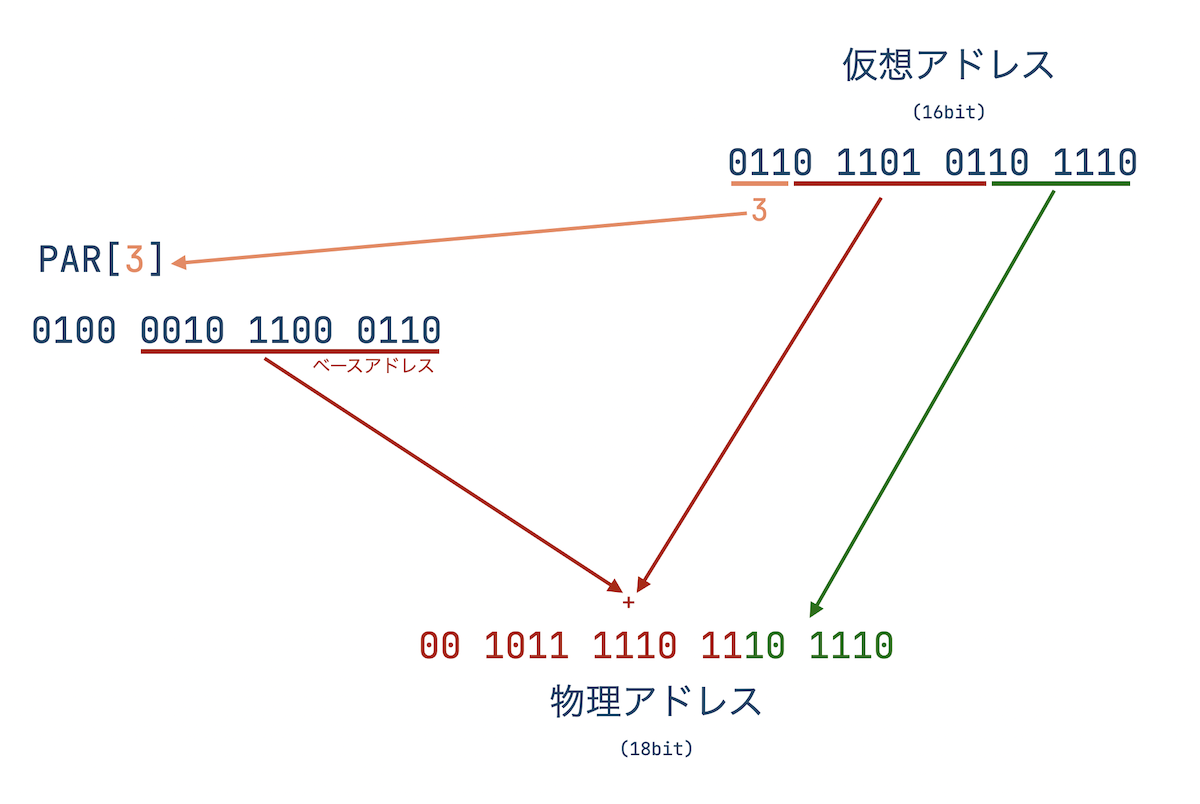
また、グローバル変数u (= 0140000)で実行中プロセスのuserにアクセス可能です。
この0140000はprefixに 0 がある通り8進数であり、2進数に直すと1100000000000000という16bitの仮想アドレスです。
この仮想アドレスを物理アドレスに変換した際に、実行中プロセスのuserを指すようになっています。
仕組みとしては、先頭の3bitは 110 (= 6) ですので、APR[6] が該当し、それ以降は全て0なので、APR[6] の先頭を指します。
このAPR[6]の先頭を、カーネルモード用のAPRにおいて「実行中プロセスのuser」と設定しているようです。
プロセスのライフサイクル
プロセスは小プロセスを生成することができます。
このプロセスの親子関係を作るのに大事な関数が fork() です。
forkは2種類あって、1つはアセンブリで書かれたCライブラリの source/s4/fork.s 、そしてカーネルプロセスで扱うCで書かれた sys/ken/sys1.cのforkです。
ここからは、この2つをそれぞれ fork.s とfork.c と記述します。
Unix v6コード中でよく見られる i = fork();のようなコールは fork.s の方をコールしています。
その後、fork.s 内の sys fork で fork.c のfork()がコールされるようです。
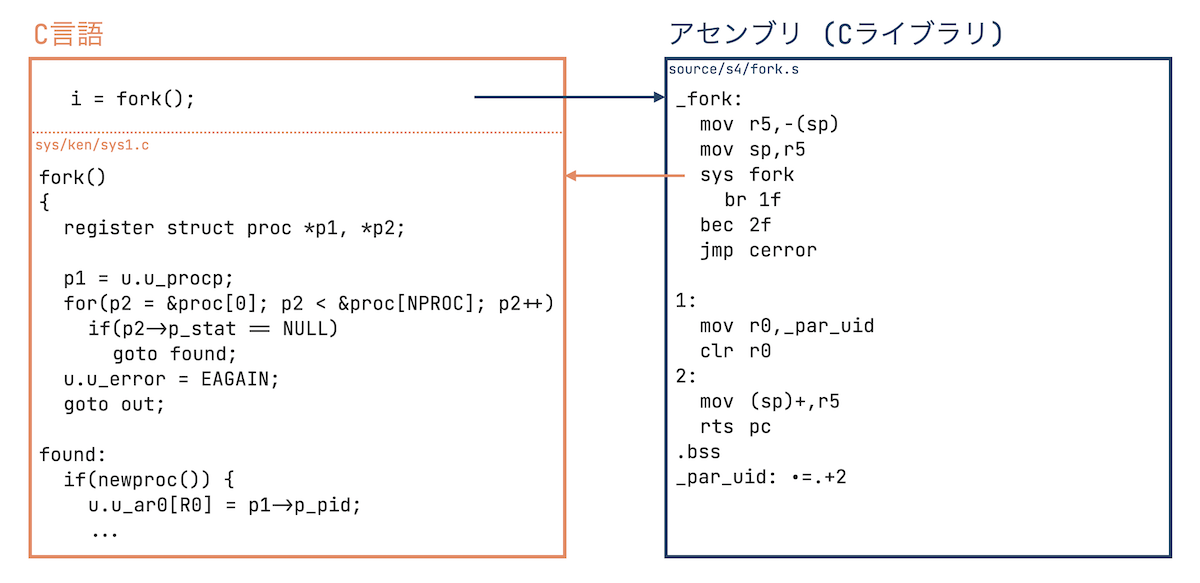
実際に、自分でC言語で同じようなプロセス生成コードを書いて実行ができます。
下記コードは fork関数がどうやってプロセスを分割しているか というブログを参考にさせていただきました。
#include <stdio.h>
#include <unistd.h>
#include "sys/wait.h"
int main() {
printf("main():\n");
pid_t pid = fork();
printf("fork() is called (pid=%d).\n", pid);
if (pid == 0) {
sleep(1);
printf(" - child process.\n");
return 0;
}
printf(" - parent process.\n");
int status;
waitpid(pid, &status, 0);
printf(" - parent end\n");
return 0;
}
上記はC99での実装なので少しpre K&Rとは異なりますが、実行結果は下記のようになりました。
main():
fork() is called (pid=14184).
- parent process.
fork() is called (pid=0).
- child process.
- parent end
このようにfork()以下が二度実行され、親プロセスでは戻り値が小プロセスのPIDに、小プロセス内では戻り値は0となりました。
そして、wait() (上記はC99での記法なのでwaitpid()) で小プロセスの終了を待っています。
ちなみに unistd.hはUnix Standard Libraryのヘッダライブラリで、私はmacOSで動作確認しました。
余談: .bss
fork.sの方に出てくる .bssですが、Block Started by Symbolの略称らしいです。
Wikipediaによると
.bssまたはbssとは、静的にアロケートされた変数のうちプログラムの開始時に0で初期化されているものを含むデータセグメント内の1つのメモリ領域に付けられた名前である。Unix系や Windows を含め、多くのコンパイラやリンカがこの名前を使う。bssセクションあるいはbssセグメントと呼ばれることも多い。
(https://ja.wikipedia.org/wiki/.bss)
とのこと。
「データセグメント内の1つのメモリ領域」であり、初期値0 (=NULL)のものを指すようです。
初期値が0だと、実行ファイルにはそれ専用のメモリ領域は確保されず、実行時にプログラムをメモリに読み込むときにメモリ領域が確保されるらしいですが、このあたりはあまりイメージしにくいですね。
あとは、書籍には “bssはデータ領域に格納される” と書いてありますので、現段階ではこのあたりを頭に入れておけば良さそうです。
また、逆に0以外で初期化された変数は data と呼ばれるメモリ領域に格納されるようです。
実際にコードに紐づけると下記のようになります (ヒープ領域についてはまたいずれ)。
int a; // bss: 静的に配置されていて、なおかつ0で初期化された変数
int b = 1; // data: グローバル変数
func() {
static int c = 2; // data: static変数
int d = 3; // stack: ローカル変数
}第1,2,3章の個人的メモ:あとがき
やっぱり、初学者にはなかなかスムーズに読めないですこの本。
でも、読んでると「あーーなるほどね〜」という気づきがあるので、面白いには面白い。
3章は実はまだ、newproc()などの主要関数の説明が続くのですが、そのあたりまとめると長くなってしまうので、一旦ここで終わり。
次は3章の続きをまとめながら読み進めます。